"#KarenHao only really gets her teeth into this point in the book’s epilogue, “How the Empire Falls.” She takes inspiration from #TeHiku, a #Māori AI #speechrecognition project. Te Hiku seeks to revitalize the #te_reo language through putting archived audio tapes of te reo speakers into an AI model, teaching new generations of Māori.
The tech has been developed on consent and active participation from the Māori community, and it is only licensed to organizations that respect Māori values"
#speechrecognition
@thelinuxEXP I really like Speech Note! It's a fantastic tool for quick and local voice transcription in multiple languages, created by @mkiol
It's incredibly handy for capturing thoughts on the go, conducting interviews, or making voice memos without worrying about language barriers. The app uses strictly locally running LLMs, and its ease of use makes it a standout choice for anyone needing offline transcription services.
I primarily use #WhisperAI for transcription and Piper for voice, but many other models are available as well.
It is available as flatpak and https://github.com/mkiol/dsnote
#TTS #transcription #TextToSpeech #translator translation #offline #machinetranslation #sailfishos #SpeechSynthesis #SpeechRecognition #speechtotext #nmt #linux-desktop #stt #asr #flatpak-applications #SpeechNote

Gallaudet News: Gallaudet experts drive accessibility of speech tech for deaf voices . “Some people use their voices to control tech, from cell phones and remote controls to home appliances and in transportation. Voice command capabilities are made possible through training AI and machine learning. The Speech Accessibility Project is creating datasets of more diverse speech patterns, which […]
DeepSpeech Is Discontinued
https://github.com/mozilla/DeepSpeech
#HackerNews #DeepSpeech #Discontinued #Mozilla #AI #SpeechRecognition #MachineLearning
Going live at 4 PM Central to build a real-time speech-to-text app using SwiftUI and iOS 26 APIs.
I’ll walk through everything—mic permissions, live transcription, and Apple’s speech recognition tools.
No delay, no post-processing. Just fast, accurate voice-to-text in SwiftUI.
Watch live: https://www.youtube.com/watch?v=vIqZq1UYBOA
Hit “Notify Me” to join in.
#SwiftUI #iOSDev #SpeechRecognition #LiveCoding #Accessibility
🔊 Sunrise Technologies offers AI-powered ASR with 95%+ accuracy for real-time & offline transcription across 50+ languages. Built for healthcare, finance & more—secure, scalable, and smart.
🎯 Book a free demo
👉 https://zurl.co/WjgnT




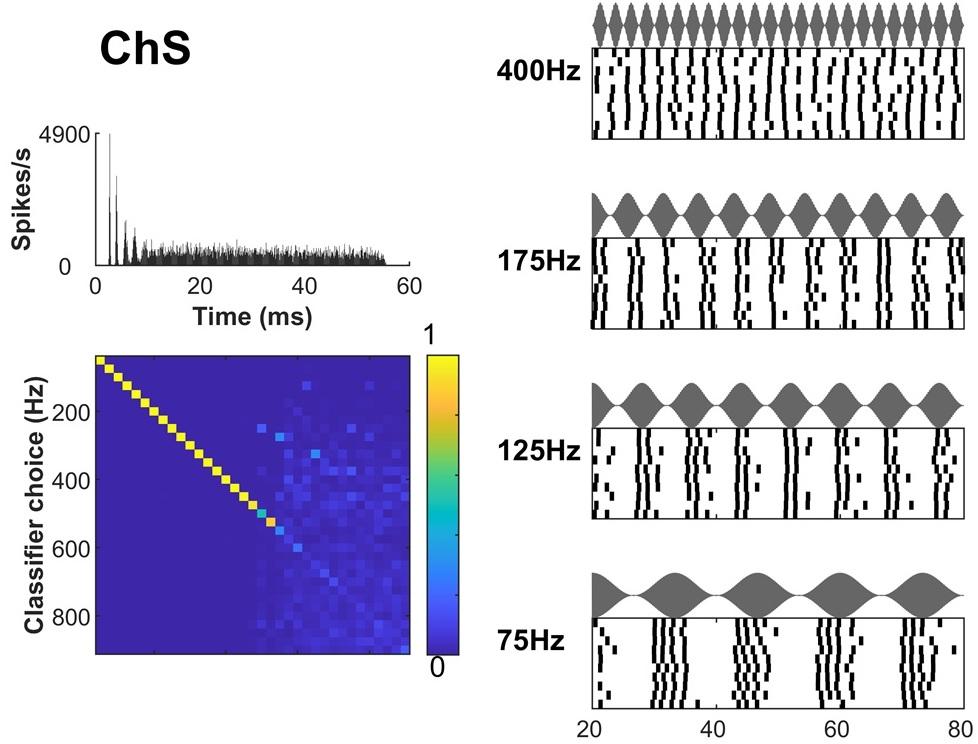
Slow amplitude fluctuations in sounds, critical for #SpeechRecognition, seem poorly represented in the #brainstem. This study shows that overlooked intricacies of #SpikeTiming represent these fluctuations, reconciling low-level neural processing with #perception @plosbiology.org 🧪 https://plos.io/3FJ4adI
The Marvel of Auditory and Cognitive Networks Working Together in Your Brain
#AuditoryProcessing #BrainScience #NeuralNetworks #CognitiveScience #Hearing #SpeechRecognition #BrainPlasticity #CentralNervousSystem #SoundProcessing #Neuroscience #ListeningSkills #BrainHealth #AuditoryDisorders #LearningAndMemory
🌟 Excited to share Thorsten-Voice's YouTube channel! 🎥 🗣️🔊 ♿ 💬
Thorsten presents innovative TTS solutions and a variety of voice technologies, making it an excellent starting point for anyone interested in open-source text-to-speech. Whether you're a developer, accessibility advocate, or tech enthusiast, his channel offers valuable insights and resources. Don't miss out on this fantastic content! 🎬
follow hem here: @thorstenvoice
or on YouTube: https://www.youtube.com/@ThorstenMueller YouTube channel!
#Accessibility #FLOSS #TTS #ParlerTTS #OpenSource #VoiceTech #TextToSpeech #AI #CoquiAI #VoiceAssistant #Sprachassistent #MachineLearning #AccessibilityMatters #FLOSS #TTS #OpenSource #Inclusivity #FOSS #Coqui #AI #CoquiAI #VoiceAssistant #Sprachassistent #VoiceTechnology #KünstlicheStimme #MachineLearning #Python #Rhasspy #TextToSpeech #VoiceTech #STT #SpeechSynthesis #SpeechRecognition #Sprachsynthese #ArtificialVoice #VoiceCloning #Spracherkennung #CoquiTTS #voice #a11y #ScreenReader
Goode @thorstenvoice, just found your channel and I'm impressed! Your work on TTS is fantastic and so important for accessibility in the FLOSS community. Keep it up! #AccessibilityMatters #FLOSS #TTS #OpenSource #Inclusivity #FOSS #Coqui #AI #CoquiAI #VoiceAssistant #Sprachassistent #VoiceTechnology #KünstlicheStimme #MachineLearning #Python #Rhasspy #TextToSpeech #VoiceTech #STT #SpeechSynthesis #SpeechRecognition #Sprachsynthese #ArtificialVoice #VoiceCloning #Spracherkennung #CoquiTTS #voice #a11y #ScreenReader
Jargonic Sets New SOTA for Japanese ASR
https://aiola.ai/blog/jargonic-japanese-asr/
#HackerNews #Jargonic #SOTA #Japanese #ASR #AI #Technology #SpeechRecognition #Innovation
Nvidia Releases High-Speed Parakeet AI Speech Recognition Model, Claims Top Spot on Leaderboard
#Nvidia #AI #ASR #SpeechRecognition #SpeechToText #OpenSource #MachineLearning #Parakeet #NeMo #HuggingFace #AIModels

Yesterday, I ordered food online. However it went a little off. And I contacted Support. They called me and for one moment, I thought it's a bot or recorded voice or something. And I hated it. Then I realized it's a human on the line.
I was planning to do an LLM+TTS+Speech Recognition and deploy it on A311D. To see if I can practice british accent with it. Now I'm rethinking about what I want to do. This way we are going, it doesn't lead to a good destination. I would hate it if I would have to talk to a voice enabled chatbot as support agent rather than a human.
And don't get me wrong. Voice enabled chatbots can have tons of good uses. But replacing humans with LLMs, not a good one. I don't think so.
#LLM #AI #TTS #ASR #speechrecognition #speechai #ML #MachineLearning #chatbot #chatbots #artificialintelligence
I'm exploring ways to improve audio preprocessing for speech recognition for my [midi2hamlib](https://github.com/DO9RE/midi2hamlib) project. Do any of my followers have expertise with **SoX** or **speech recognition**? Specifically, I’m seeking advice on: 1️⃣ Best practices for audio preparation for speech recognition. 2️⃣ SoX command-line parameters that can optimize audio during recording or playback.
https://github.com/DO9RE/midi2hamlib/blob/main/tests/speech_menu.sh #SoX #SpeechRecognition #OpenSource #AudioProcessing #ShellScripting #Sphinx #PocketSphinx #Audio Retoot appreciated.
After my #wake_word_detection #research has delievered fruits, I have plans to continue works in the voice domain. I would love if I could train a #TTS model which has #British accent so I would use it to practice.
I was wondering if I could do the inference on #A311D #NPU. However, as I am skimming papers of different models, having inference on A311D with reasonable performance seems unlikely. Even training of these models on my entry level #IntelArc #GPU would be painful.
Maybe I could just finetune an already existing models. I am also thinking about using #GeneticProgramming for some components of these TTS models to see if there will be better inference performance.
There are #FastSpeech2 and #SpeedySpeech which look promising. I wonder how much natural their accents will be. But they would be good starting points.
BTW, if anyone needs opensource models, I would love to work as a freelancer and have an #opensource job. Even if someone can just provide access to computation resources, that would be good.
#forhire #opensourcejob #job #hiring
#AI #VoiceAI #opensourceai #ml #speechrecognition #speechsynthesis #texttospeech #machinelearning #artificialintelligence #getfedihired #FediHire #hireme #wakeworddetection
Quand je passe par la commande vocale pour ajouter du VIANDOX à la liste de courses 🤦♂️
Jargonic: Industry-Tunable ASR Model
https://aiola.ai/blog/introducing-jargonic-asr/
#HackerNews #Jargonic #ASR #Industry #AI #Model #SpeechRecognition
T-Pro Expands Footprint in India with New AI-Powered Healthcare Offices in Chennai and Bangalore
#TProExpansion #HealthcareInnovation #AIinHealthcare #ClinicalDocumentation #GlobalGrowth #AIResearch #MedtechIndia #DigitalHealth #IrelandIndiaPartnership #ChennaiTech #BangaloreInnovation #AIForHealth #EnterpriseIreland #SpeechRecognition #MedtechSolutions #HealthcareAI #FutureOfHealthcare #TechExpansion #IrishMedtech #HealthcareRevolution
Vibe is an #OpenSource desktop client (mac, windows, linux) for locally running Whisper to more accurately transcribe or caption videos & audio https://thewh1teagle.github.io/vibe/ Source code: https://github.com/thewh1teagle/vibe/ Easier to use than what I was using before (WhisperDesktop). Default settings use the medium Whisper model, which has been good enough in my experience.
#Accessibility #A11y #AI #SpeechRecognition #EdTech
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst