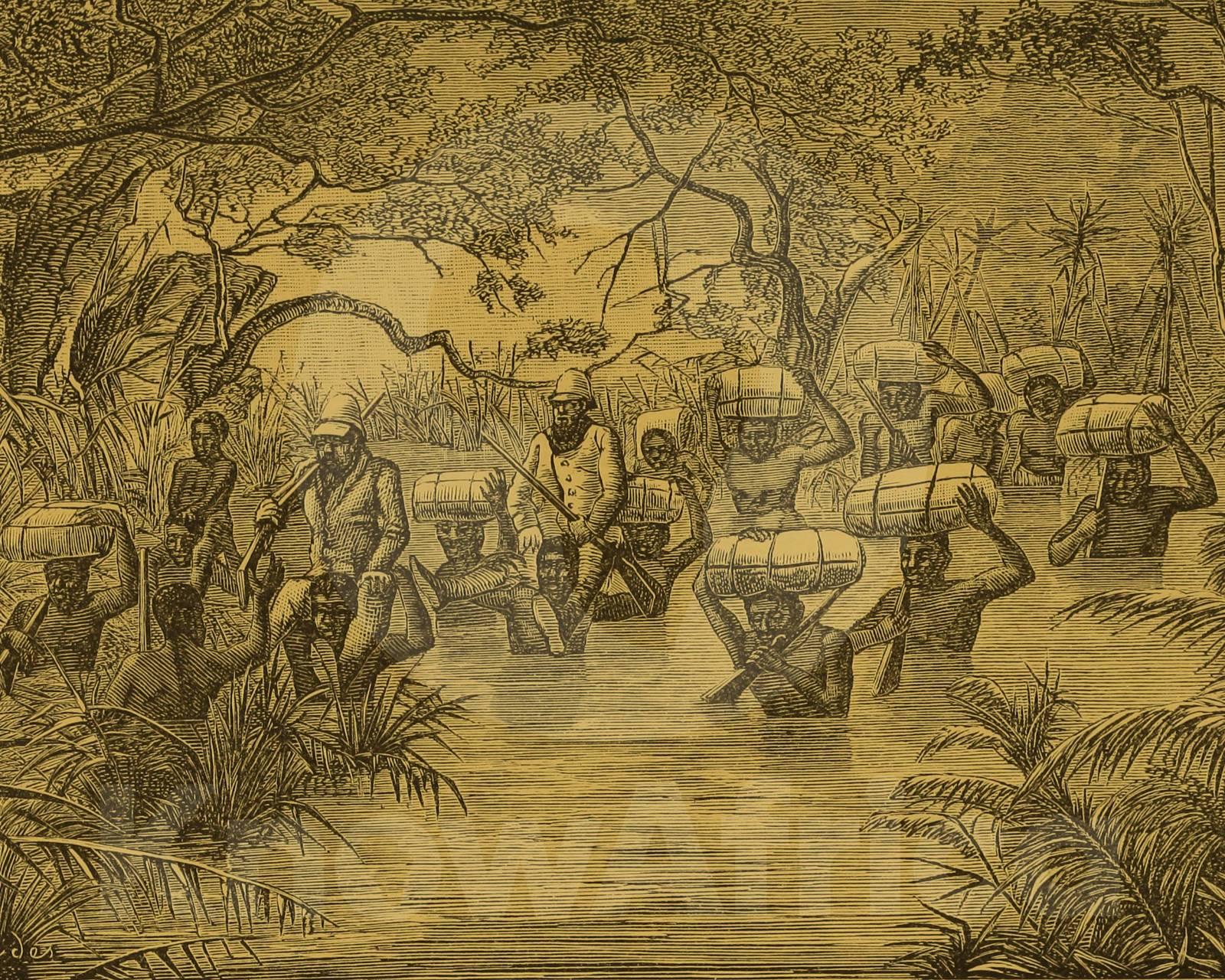I finally finished reading "The Invention of Nature" yesterday, having been a bit slow due to the other books I read alongside it.
It's really good, and if you're not aware of both Alexander von Humboldt (not the sail training ship, (a.k.a. Alexander von Becks - if anyone remembers those TV adverts with the barque with a green hull and green sails), but its namesake) and his influence on Darwin, Muir and others, I'd recommend it. We should have been taught about him, and Marsh, Haeckel and Muir, in school; they should be household names - as indeed Humboldt was in his day - hence the Humboldt current, and many other things named after him .
Though I'm not 100% convinced there are more things named after von Humboldt than anyone else - I think he's probably pipped to the post by a chap from Nazareth.
#Books #Reading #HistoryOfScience #ClimateChange #Biodiversity #TheInventionOfNature