Just did my best to try and infect the @weirdfictionquarterly.com writers with Roko's Basilisk.
In one box is the theme of WFQ's Summer 2025 issue. In the second is...
#RokosBasilisk #LessWrong #TimelessDecisionTheory #WeirdFictionQuarterly #Singularity #AGI #ArtificialIntelligence
The Most Terrifying Thought Ex...
#LessWrong
Recent AI model progress feels mostly like bullshit
#HackerNews #AI #Progress #AI #Models #Critique #Technology #Discussion #LessWrong
It always ends up the same way, "I should do what I want, and I want to do cruel, weird shit to other people without their consent"
Yawn.

These techno-cults are better than fiction.
https://maxread.substack.com/p/the-zizians-and-the-rationalist-death
#lesswrong #tescreal
You've finally saved enough #money for that #Swasticar you've always wanted but thanks to Felon MuSSk it's #NotCool anymore.
What to do?
Why not consider buying another brand of car for which nature and people have been exploited?
Still wrong, but so much #LessWrong!
What are you waiting for? Thanks to the orange clown the prices of #cars in the Divided States will soon skyrocket! (To Mars)
Or... you can just do everything by bike and use your savings to build a nuclear shelter 🤔
Fascinating! 😇

lol of course the rationalist reporter kelsey piper supports james damore. rationalists have never met a sexist/racist/etc computer toucher they didn't like. #rationalism #lesswrong #effectivealtruism
потерял точилку на кухне
интересно, есть ли "рациональные" способы поиска потерянного? (точилка подарок, поэтому есть эмоциональная привязанность)
получил обновление своих убеждений о мире и о своих навыках искать точилку
hello!
i’m ainslee. i’m new in town…
i spend time in these places
#lasvegas #reno #nevada #losangeles
i study these things
#datascience #data #computers #compsci #comptia #ai #llm #aiethics #statistics #redistricting #pitzercollege #5cs
i do this stuff when i have free time
#blog #soldering #linux #manjaro #BikeTooter #biking #raspberrypi #defcon
i like reading about these
#technews #gadgetsnews #theverge #copyright #socialweb #lesswrong #effectivealtruism #infosec #uspol #nvpol
i am trying to be these things
#sysadmin #it #gradschool #unr
say hi maybe?
Liquid vs Illiquid Careers — LessWrong
https://www.lesswrong.com/posts/Sdi7gkKSHkRspqqcG/liquid-vs-illiquid-careers
You don't know how bad most things are nor precisely how they're bad
https://www.lesswrong.com/posts/PJu2HhKsyTEJMxS9a/you-don-t-know-how-bad-most-things-are-nor-precisely-how
https://news.ycombinator.com/item?id=41311135
Interesting read about piano tuning
#LessWrong is a community blog focused on "refining the art of human #rationality." To this end, it focuses on identifying and overcoming bias, improving judgment and problem-solving, and speculating about the future. The blog is based on the ideas of Eliezer Yudkowsky, a research fellow for the Machine Intelligence Research Institute (MIRI; previously known as the Singularity Institute for Artificial Intelligence, and then the Singularity Institute). Many members of LessWrong share Yudkowsky's interests in #transhumanism, artificial intelligence (AI), the #Singularity, and #ai
#RationalWiki #miri #ai
https://rationalwiki.org/wiki/LessWrong


Разобрался в основном с алгоритмом обучения gradual value/policy iteration, прикольненький.
https://gibberblot.github.io/rl-notes/single-agent/policy-iteration.html тут что-то про него
Всё ради того, чтобы разобрать статью. Какого формата статья?
"Смотрите, круто если мы будем reward при обучении с подкреплением не максимизировать, а делать равным чему-то. Вот как это делать. Оказывается, если выбирать интервал, то получается много способов это сделать. Тогда можно наложить всяких ограничений по безопасности, чтобы не улететь по случайности в ту или иную сторону, или не выбирать слишком хардовые шаги и тд"
Jack Dorsey, Bluesky, decentralised social networks and the very common crowd https://davidgerard.co.uk/blockchain/2024/05/10/jack-dorsey-bluesky-decentralised-social-networks-and-the-very-common-crowd/ #Bluesky, #DonaldTrump, #ElonMusk, #FreedomFund, #JackDorsey, #Lesswrong, #Mastodon, #MikeSolana, #Neoreaction, #Nostr, #PaulFrazee, #PeterThiel, #PirateWires, #RichardSpencer, #RobertF.KennedyJr, #Twitter, #Vibecamp
a bit of embroidery after a few months of hiatus.
I think this is the most important question we all need to ask ourselves.
"What do you think you know and how do you think you know it?"
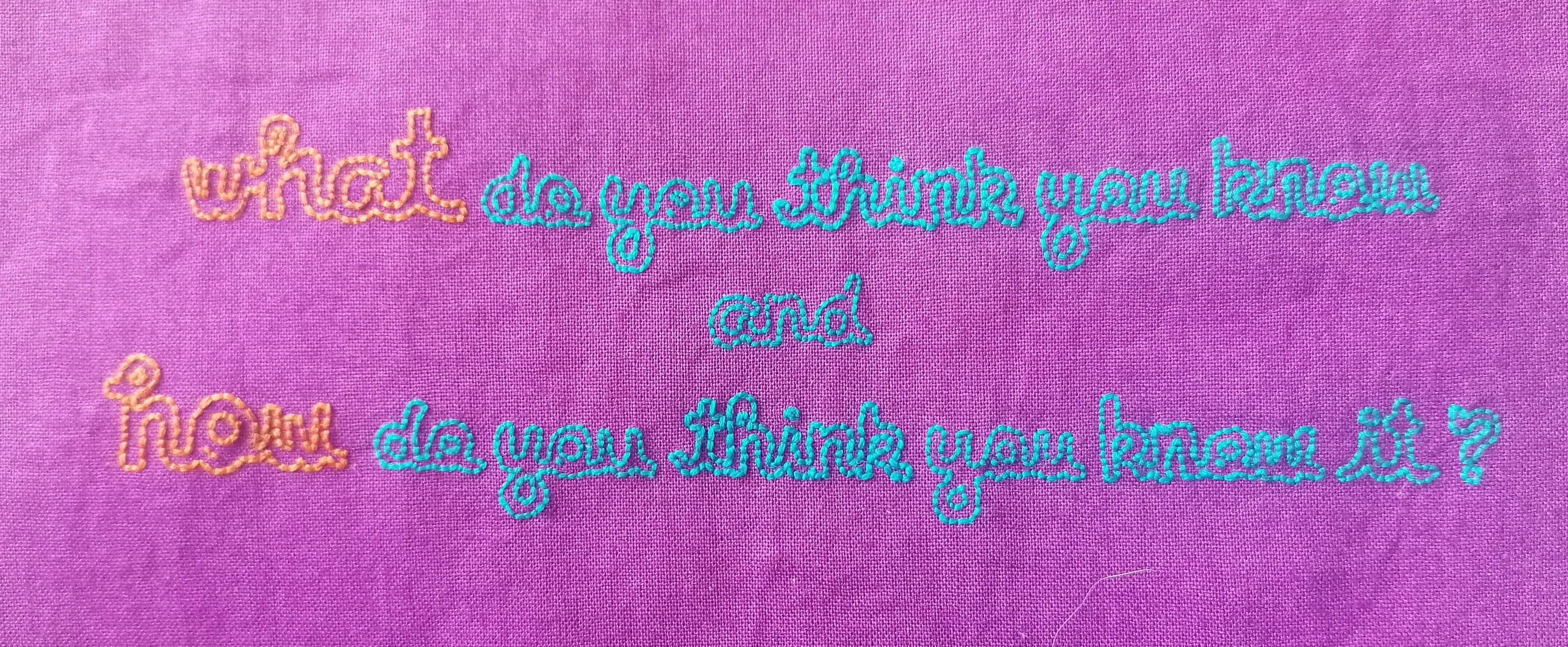
On #Rationalism, #EffectiveAltruism, and #PostRationalism:
“Rational Magic”, The New Atlantis (https://www.thenewatlantis.com/publications/rational-magic).
#EliezerYudkowsky #MetaTribe #Rationality #LessWrong #OvercomingBias #SlateStarCodex
@futurebird
'Terraforming earth' would get a lot more people interested but it would also be like shit for flies to the #ExistentialRisk / #Longtermism / #LessWrong / #TESCREAL crowd. You'd almost immediately see it coopted to advocate for building a bunch of fusion-fueled domed cities populated by white people designign a brave new future filled with computronium-maximizing nanoassemblers & simulated humans living simulations of lives optimized for maximum neo-Utilitarian 'happiness.'
The unrivaled leaders in modern Sophistry
https://mathstodon.xyz/@pmigdal/109319874918794086
#LessWrong #Rationalism #TESCREAL
#LessWrong-ism leads to thinking GPTs get more creative when they're hot.
#WisdomAccelerationism (a play on #EffectiveAccelerationism or maybe just #Accelerationism - taking either one seriously enough to fix it by substituting 'wisdom' is a little concerning, especially given the apparent belief that GPTs are 'creative.')
![Screenshot of a tweet:
[twitter display name obscured] [paid icon] [twitter id obscured]
| wonder why increasing temperature in GPTs seems to produce slightly better results? It's as if a bit of entropy enhances creativity. Does this have implications on human cognition? Do we rely on quantum or chaotic process randomness for creativity?](https://files.mastodon.social/media_attachments/files/110/299/459/373/485/166/original/6be114b53d0de5c3.png)
![Screenshot from a twitter profile bio:
[twitter display name obscured] [paid icon] [twitter id obscured]
[begin highlight] wisdom accelerationist (w/acc] [end highlight] sensemaking futurst seeking meaning and balance in the meta-crisis « complexity, #WardleyMaps « he/any](https://files.mastodon.social/media_attachments/files/110/299/465/292/226/728/original/179554d597afc40d.png)
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst